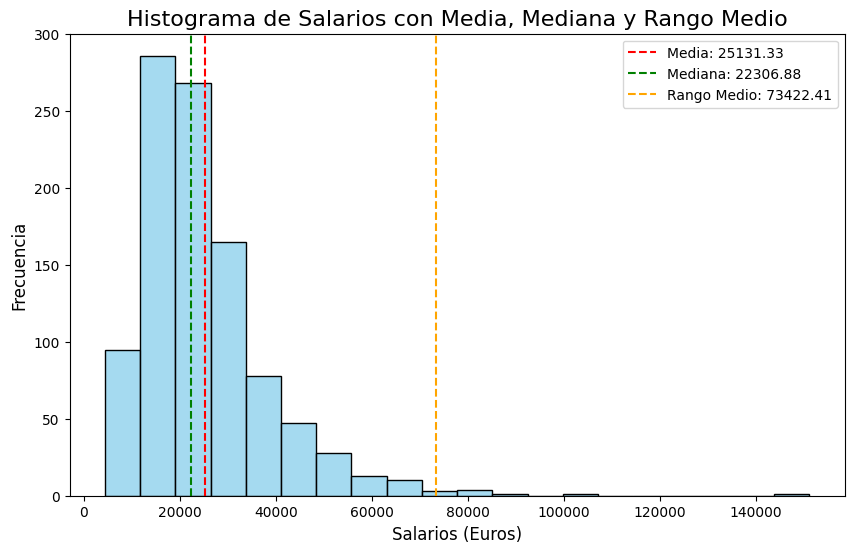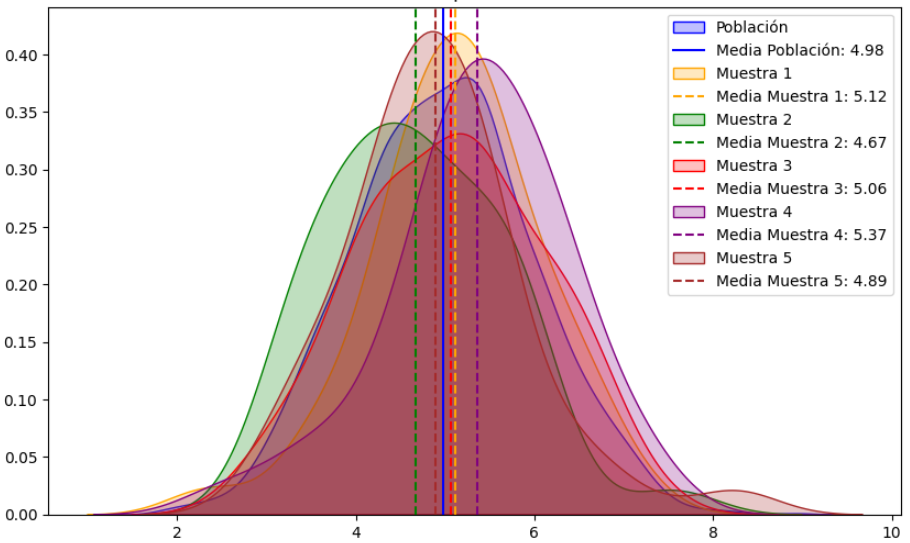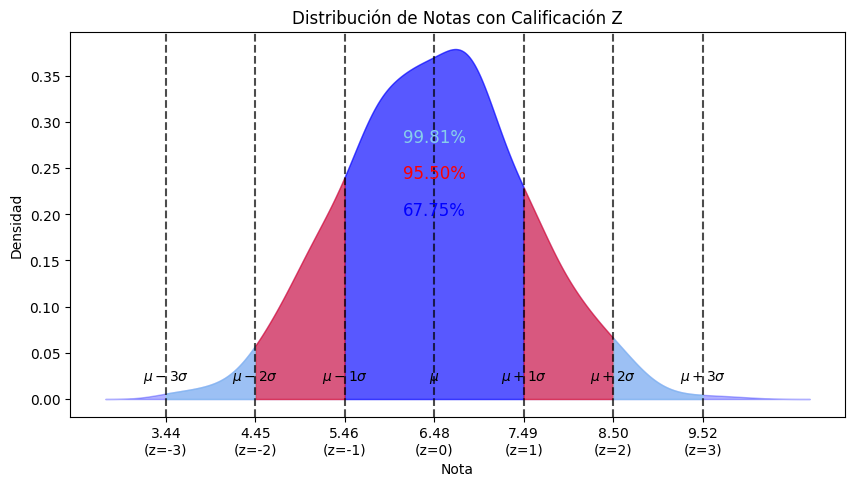
En julio de 2025, y como parte de la serie dedicada a la Ciencia de Datos, publiqué en el blog de Datarmony el artículo Data Science II-E: Estadística descriptiva unidimensional. La curva normal. En él se hace un repaso de las apariciones del concepto de normalidad (en la acepción estadística del término) en los artículos publicados hasta ese momento, desde sus primeros atisbos gráficos, donde mencionamos la consabida «forma de campana», hasta su definición empírica:
«Si una variable está normalmente distribuida, entonces (1) dentro de una desviación estándar de la media habrá aproximadamente un 68% de los datos; (2) dentro de dos desviaciones estándar de la media habrá aproximadamente un 95% de los datos; y (3) dentro de tres desviaciones estándar de la media habrá aproximadamente un 99.7% de los datos» (Johnson & Kuby, 2008).
Acabado el repaso, el artículo se adentra en el estudio de la distribución normal teórica, tanto desde una perspectiva histórica, donde se mencionan las contribuciones de de Moivre, Laplace y Gauss al concepto, como desde una perspectiva matemática, momento en el cual se analiza la función de densidad normal.
El artículo acaba con un estudio de las medidas de forma y concentración (simetría y curtosis, respectivamente), con el objetivo de aportar una visión completa y rigurosa del tema.