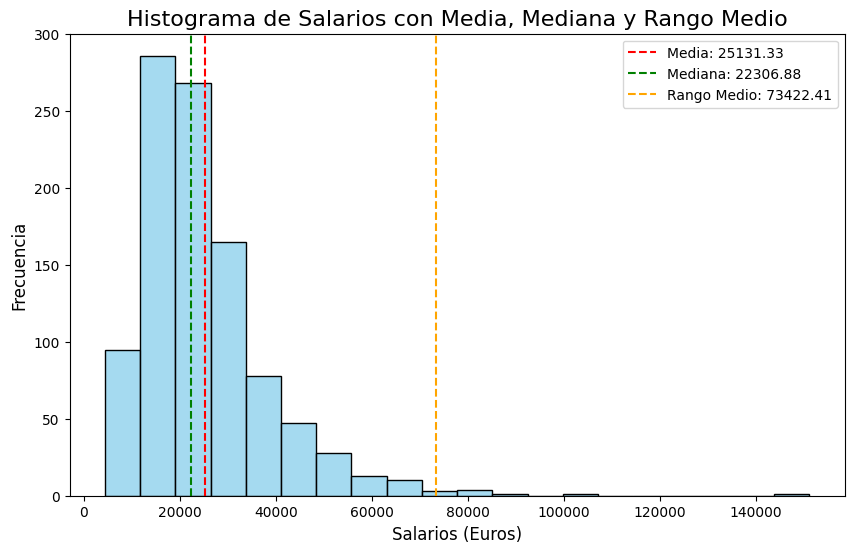
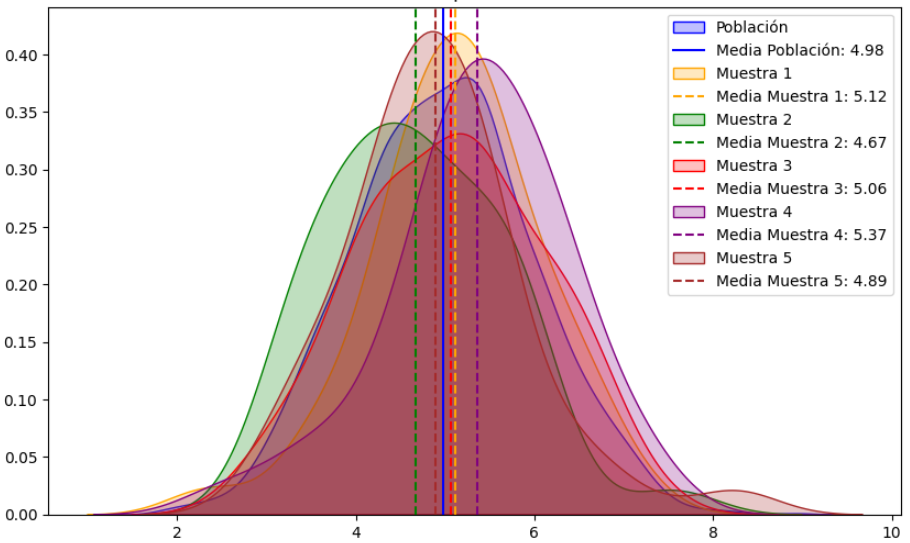
A partir de un conjunto de datos ficticios, pensados para ejemplificar los conceptos, explico qué es una tabla de frecuencias y cómo se construye definiendo sus elementos uno por uno:
Frecuencia absoluta (n_i): número de veces que aparece un valor
Frecuencia absoluta acumulada (N_i): suma de las frecuencias absolutas de los valores iguales o inferiores.
Frecuencia relativa (f_i): proporción de veces que aparece un valor sobre el total.
Frecuencia relativa acumulada (F_i): Suma de las frecuencias relativas, indicando la proporción de valores iguales o inferiores.
Cuando la variable adquiere muchos valores distintos, como es el caso en los datos de ejemplo, es conveniente agrupar los datos con el objetivo de simplificar el análisis. En el texto presento un procedimiento adecuado de agrupación de variables.
Finalmente, repaso en detalle los gráficos de frecuencia, en concreto los histogramas, y muestro los métodos más comunes para establecer el número óptimo de contenedores:
Método de la raíz cuadrada (adecuado para conjuntos de datos pequeños)
Criterio de Sturges (para conjuntos de datos grandes).
El 29 de julio de 2024 inicié la publicación de una serie de artículos sobre Ciencia de Datos, en el blog de Datarmony. En el primero se repasan los conceptos estadísticos básicos, y se subraya la necesidad de dominar los conceptos estadísticos fundamentales antes de abordar herramientas avanzadas de modelización de datos.
Ha llovido mucho desde entonces, y los modelos de generación de imágenes han mejorado bastante (aunque, desde mi punto de vista, todavía tienen terreno por recorrer).
Con un tono desenfadado, analizaba los resultados de los prompts, demostrando que, a pesar de la euforia, los resultados eran bastante pobres.
En este artículo publicado en LinkedIn en febrero de 2022, reflexiono sobre la drástica evolución de la Inteligencia Artificial desde 2018 hasta ese momento. En aquel entonces, la IA se centraba en el Machine Learning, una tecnología potente pero principalmente accesible para grandes corporaciones como Google o Amazon, y alejada del usuario común. Las aplicaciones más avanzadas, como las redes neuronales profundas, estaban en sus inicios y no existía nada parecido a la IA Generativa actual.
Un concepto clave que ya se debatía era el Test de Turing. En 2018, argumentaba que una IA nunca podría superarlo debido a una contradicción fundamental: para ser útil, se esperaba que una IA fuera perfecta y no cometiera errores, pero una entidad sin fallos sería fácilmente identificada como una máquina, no como un humano. Por lo tanto, una IA «inteligente» en términos humanos parecía imposible.
Sin embargo, la irrupción de modelos como ChatGPT y Gemini cambió por completo mi perspectiva. Estas nuevas tecnologías se acercan a superar el Test de Turing precisamente porque cometen errores. Sus «alucinaciones», interpretaciones incorrectas y falsedades son fallos que, paradójicamente, las hacen más parecidas a los humanos.
Esto revela una nueva paradoja: las empresas tecnológicas compiten por perfeccionar sus modelos y eliminar los errores, un objetivo que, de lograrse, haría que sus IA no pasaran el Test de Turing al carecer de la falibilidad humana.
Logos de BigQuery y Google Analytics. Fuente: google.com
El 1 de julio de 2024 Google completó la migración de Universal Analytics a GA4. Los meses anteriores fueron un verdadero via crucis para muchas empresas, y sus consultores de analítica web. En esa guerra, librada, sobre todo, contra el tiempo, una de las batallas más cruentas fue la que enfrentó a los datos que se recogían de GA4 y su reflejo en las tablas de BigQuery.
Ante la desaparición en la interfaz de GA4 de muchos de los informes a los que Universal nos tenía acostumbrados, la reacción natural fue intentar montarlos en alguna herramienta de visualización de datos o Business intelligence, a partir de las tablas de BigQuery que se creaban gracias a la exportación automática de datos entre ambas plataformas.
Para mi proyecto final del curso Professional Certificate in Data Science, decidí abordar el desafío de predecir accidentes cerebrovasculares (ACV). El principal problema que encontré fue un severo desbalance de clases en el conjunto de datos: solo el 4% de los casos eran positivos para ACV. Esto hacía que cualquier modelo simple fuera inútil, ya que podía lograr un 96% de precisión simplemente prediciendo «no-stroke» en todos los casos.
Como decía ya en la entrada anterior, este blog ha estado dormido varios años. No es que haya dejado de escribir, es que he estado probando otras plataformas.
Este blog ha estado dormido varios años. No es que haya dejado de publicar cosas, sino que he estado probando otras plataformas.
En febrero de 2021, publiqué en LinkedIn un artículo en el que resumía la evolución de Google Analytics, desde la adquisición de Urchin hasta la agónica migración a Google Analytics 4, que no solo fue una actualización técnica, si no un cambio de paradigma de medición que reflejaba las tendencias en el análisis de datos y la estrategia de negocio de Google.
Se suele decir que Leonardo Da Vinci fue el último de los genios que dominó gran parte del saber humano de su época. De hecho, yo creo que más que el último, fue el único. En cualquier caso, parte de su fama se la debe no tanto a lo que sabía, si no a que era un genio.
Genio o no, actualmente es imposible encontrar a alguien que domine, como hizo Da Vinci en la suya, gran parte del saber humano de esta época. Ni siquiera Leonardo lo conseguiría hoy en día. Demasiados datos, demasiado saber. Read More